Modularity
Slide Deck: Modularity
Modularity
As we mentioned before, modularity refers to our desire to break up our big problem into smaller problems. We will look at two types of decomposition: functional and class decomposition.
Motivating Example
For the remainder of this unit, I will use the motivating example of Homework 1A/B from Fall ‘22 semester of CS 3140 at the University of Virginia
In this unit, we will often discuss design from the perspective of the above problem. A summary of this problem is:
“Given state names and populations and a number of representatives to allocate, produce an apportionment for the US House of Representatives.”
We will use this question to explore ideas of modularity, functional independence, abstraction, and information hiding.
Functional Decomposition
Functional decomposition is the practice of breaking up a complicated functional process into smaller functions. Often, we start with a major goal, like “generate an apportionment of representatives for the US Congress based upon state populations”.
In general, we can start breaking things down in a top-down breadth-first way. That is, we don’t need to figure out every single module we are writing immediately. Rather, we can decompose our highest-level module into lower level modules, and then decompose each sub-module, until we end up with modules that cannot be made easier to understand by further decomposition. We covered code level examples of functional decomposition in our Extract Method unit. However, in this unit, I don’t want us specifically thinking about code, as the process of functional decomposition is not tied to any one specific language.
For instance, let’s consider the process of applying the Hamilton/Vinton Apportionment method
The description of this approach would be (quoting the above website):
“The Hamilton/Vinton Method sets the divisor as the proportion of the total population per House seat. After each state’s population is divided by the divisor, the whole number of the quotient is kept and the fraction dropped. This will result in surplus House seats. The first surplus seat is assigned to the state with the largest fraction after the original division. The next is assigned to the state with the second-largest fraction and so on.”
Now, that sound like a lot of steps, so let’s try to break it down:
1) Get the divisor, which is the proportion of total population per House 2) Allocate the initial seats by dividing each state’s population by the divisor and rounding down 3) Allocate surplus seats in order of remainder
Each of these problems are smaller, and I can start to imagine function signatures for them. For the below code, assume that each State describes a state by it’s name and population.
//overall function
public HashMap<State, Integer> getHamiltonApportionment(List<State> states, int seatCount) { ... }
//step 1
public double getDivisor(List<State> states, int seatCount) { ... }
//step 2
public HashMap<State, Integer> getInitialSeats(List<State> states, double divisor) { ... }
//step 3
public HashMap<State, Integer> getRemainingSeats(HashMap<State, Integer> initialApportionment, double divisor, int seatsRemaining) { ... }
Notice that each step provides some information the next step needs. For instance, we need the divisor from Step 1 to complete step 2 and step 3. In this way, we are defining a sequence of events.
We can decompose this step further. For example, consider Step 1. How do we get the divisor? Well, we:
1) Get the total population by summing each state’s population. 2) Divide the total population by the number of seats needed and return the quotient
In the same way, we can decompose our other two steps. We often visually represent this as a tree:
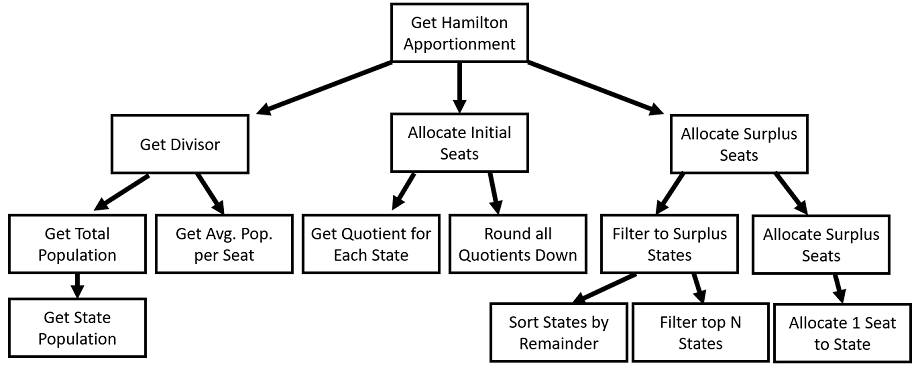
This diagram can describe our functional decomposition. At the top, we have one overarching high-level behavior. We work in a depth-first way from left to right, so we first call Get Divisor. This sort of structure can help us design our functional decomposition.
A key advantage is now it becomes easier to break up work. For example, you could assign individual functions to different developers.
Another key advantage is that as we decompose the system, we might see places where we can re-use functions. For example, getting the Quotient for each state in Step 2 will be needed to get the remainders in Step 3. The same process for allocating seats in Step 2 can be used to allocate seats in Step 3. It allows us to think about how to write more DRY code.
Limits of functional decomposition
This decomposition only shows us one part of our arching-system. While we could in theory perform a functional decomposition of our entire software system, this assumes that our software system runs in a sequence, from beginning to end, until completion. But much of software doesn’t run this way. That is, our application may be persistent, where information is saved from one-run to the next, or the application is asynchronous, relying on external interaction, such as interactions from users or from external servers. In these systems, we can do functional decomposition of individual interactions, but that alone cannot paint a complete picture of our entire software.
Another weakness is that, in this approach, each high-level function is highly dependent on each low level function. That is, it needs to know what information the function needs, and how to handle the output. However, if implementation details need to change, those changes could cascade upwards. This is fine when our tree is relatively small, but as our process gets bigger and more complicated, these changes can become harder to predict and manage.
Class Decomposition
In Object-Oriented languages, we can decompose our system into various classes, each responsible for a single behavior or action.
Note that when we say classes, we do not just mean Data Structures. For example, State in our Apportionment description above is just a Data Structure for combining data that describes a single state.
public class State {
private String name;
private int population;
public State(String name, int population) {
this.name = name;
this.population = population;
}
public String getName() { return name; }
public int getPopulation() { return population; }
}
This module’s purpose is to stored cohesive data (that is, data that describes a single state).
Beyond that, however, we may have classes that encapsulate functionality. For example, we may have a class that describes an apportionment, and has an interface that supports adding a given number of representatives to a state. Another class may be used for sorting our states based on quotient remainder, etc. We will discuss, throughout the rest of this unit, how to identify and break up classes. We covered this topic a little bit in our Extract Class unit.
Cohesiveness
Cohesiveness refers to how much each class adheres to one specific purpose. That is, how much each par For example, in our State class above, a state’s name and population are directly tied to the idea of a state. We store this data together as one unit because it describes that single purpose. The alternative would be having something like two parallel lists, List
On the other hand, let’s imagine we included the idea of quotient (that is, the state’s population divided by the divisor) in our State class.
public class State {
private String name;
private int population;
private double quotient;
public State(String name, int population) {
this.name = name;
this.population = population;
}
public String getName() { return name; }
public int getPopulation() { return population; }
public void calculateQuotient(double divisor) { quotient = population / divisor; }
public double getQuotient() { return quotient; }
}
Now, we’ve made our class less cohesive. Before, any part of our system that needs information about our State could use any part of the class they need. But now, several systems which use name and population, but do not use quotient, have to understand the reason quotient exists. In truth, we only need quotient in a specific context (i.e., Steps 2 and 3), but do not use it in ever context (Step 1). In this case, we have made our State class more specific to a particular context, and therefore less reusable in general.
Levels of Cohesion
We can describe different levels of cohesiveness by describe how we chose to combine, or couple elements into a single class.
Below, we will broadly describe different levels of cohesiveness from WORST to BEST. Note that this applies within each group. So for example, Logical cohesion, while bad, is still better than coincidental cohesion
WORST: Very loose cohesion, to be avoided
- Coincidental cohesion
- Logical cohesion
- Temporal cohesion
MODERATE: Could be better, but acceptable
- Procedural cohesion
- Communicational cohesion
BETTER:
- Sequential cohesion
BEST:
- Functional cohesion
Also note that below I am using Object Oriented class examples. However, these levels of cohesion can also describe functions.
Coincidental Cohesion (worst)
Elements are combined into a module (such as a class) by effectively coincidence. That is, a module contains elements that are not clearly related to one another. In this case, it’s likely that several modules exist within the single module we have, and we should decompose them further. Because elements are grouped that shouldn’t be, it can make reusing modules in a new context nearly impossible. Additionally, because several disparate items are grouped together, it becomes likely that changes to one part of the module could result in strange behavior in other parts of our modules.
Having one giant Main class that handles all features is a worst-case example of coincidental cohesion.
Logical cohesion
Elements are grouped into a module because they described the same general activity, or have similar interfaces, or are otherwise categorized the same.
Example, imagine that we had a class to read in state information from different sources:
public class StateReader {
public List<State> readCSVFile(String filename);
public List<State> readExcelFile(String filename);
public List<State> readJSONFile(String filename);
public List<State> readWebService(URL url);
}
On the face of it, this is better than coincidental cohesion, because at the very least we are now breaking up our modules in some fashion. After all, they all read in some data source and return a list of states. However, the implementations of each of these are largely unrelated. This means any fields or functions used by readCSVFile() are likely to be unused by any of the other functions. Thus, by grouping them together, we are
When using this module, a client is typically picking only one of these options: the reader for the source of data we have. As such, there are large portions of this module that do not contribute to the same functional purpose, as they go unused most of the time.
Temporal Cohesion
A temporally cohesive module is where items are grouped because they occur at around the same time (but not in any particular sequence), but are otherwise unrelated. For instance, let’s say we had an application that interacted with some external database, as well as a graphical user interface (GUI) and an external web server, and we decide to group all of the initialization routines for these sources into the same module.
public class Initializer {
public void initializeDatabaseConnection();
public void initializeGUI();
public void initializeRemoteServerConnection();
}
Here, these elements would better be handled in separate modules. For example, it would be better to have a module whose purpose is opening and closing the Database connection, as it relates to the functionality of handling the database connection. Similar to logical cohesion, we are grouping things whose implementations likely do not (and should not) interact with each other.
Procedural Cohesion
A module with only procedural coupling is supporting unrelated activities in which control passes from one activity to the next, ensuring they execute in a specific order. For example, consider a student registering for a course that has pre-requisites. A student can register for the course if there are seats available and they have met the pre-requisites.
public class CourseRegistration {
public StudentRecord getStudentRecord(Student student);
public List<Prerequisite> getPreRequisites(Course course);
public boolean studentMeetsAllPrerequisites(Student student, List<Prerequisite> prerequisites);
public boolean isCourseFull(Course course);
public void addStudentToCourse(Student student, course course);
}
While this is better than our other examples, it still is group elements that do not adhere to the same function. For example, getting a StudentRecord has nothing, functionally, it do with getting the prerequisite for a given course. It only matters in the specific context we have here. As such, each module is less likely to be reusable in a DRY way, as it is written as part of a procedure. If I only want one step of this procedure in another module (such as getting the StudentRecord in order to print a transcript), it is awkward and confusing to use code from this module which isn’t related to that single behavior.
Communicational cohesion
Elements are grouped together in a module simply because they perform actions on the same data for either input or output. For example,
public class StudentRecord {
public void addGrade(Course course, Grade grade);
public double getGPA();
public int getTotalCreditHour();
public void printTranscript();
public void meetsPrerequisiteForCourse(Course course);
}
Here, these features all work on the same data: the student’s course history. However, the behaviors are not tightly related to one another. For example, only a small subset of clients to this module will use each specific feature, and all or most clients of the module won’t use every feature. This makes code re-use awkward, and makes the modules larger than they need to be, forcing clients to understand which methods to not use.
Sequential cohesion
Generally, sequential cohesion is considered “fine” if not ideal.
Similar to procedural cohesion, elements are grouped because they happen in sequence, where one element’s output are directly used by the next elements inputs. That is, the elements must occur in sequence.
public Class PrintDeansListFile {
public Map<Student, Double> getStudentGPAMap();
public List<Student> getDeansListStudents(Map<Student, Double> studentMap);
public File generateDeansListPDF(List<Student> deansListStudents);
public void printFile(File deansListPDF);
}
This may look similar to procedural cohesion, but the difference is that in sequential, each of our modules elements occur in exactly one order, where output from a step is used as input in the next step.
Cohesion here is very high. However, some of the functions could be re-used in other contexts, such as getStudentGPAMap(), or even printFile(), so it may be beneficial to extract those to more functionally specific modules.
That said, when we need to enforce a specific sequence of events, sequential cohesion is necessary.
Functional cohesion
A module exhibits functional cohesion if it describes a single well-supported function. I.e., a something that only does on thing. It is certainly useful to have our functions themselves work this way. Many of our classes may work this way as well. For example:
public class PrerequisiteChecker {
public boolean isPrerequisiteMetByStudent(Prerequisite prereq, Student student);
}
In this case, this module only has one behavior, which is functional in nature (given some input, get some output). This is very maintainable, because so long as the interface remains the same, the implementation can change without propagating change to any other module. It’s also very easy to extend this behavior and have multiple implementations (using polymorphism). Additionally, the interface of this module is as simple as possible: there is only one element to this module. Ultimately, this module takes input in exactly one place, and returns exactly one piece of output.
Of course, we can’t always have every class have exactly 1 purely functional method. For example, data structure classes will typically have a constructor and getters and setters. However, when we can achieve functional cohesion, it is worth doing so.
Functional Independence
When we are decomposing our system into modules, we need to consider how our modules are integrated with each other as we bring all the modules back together. We want the interactions between modules to be as simple as possible. This is true both in functional decomposition and class decompositions.
Coupling
Coupling is the degree to which two modules interact with one another. This is different from cohesion in a key way:
cohesion: the extent to which elements in the same module are dependent on one another (high cohesion is good), or intradependency.
coupling: the extent to which elements in interacting modules are dependent on each other (loose coupling is good), or interdependency.
Types of Coupling
We also have different levels of coupling like we did cohesion. As before, we will arrange them from worst to best.
WORST
- Content coupling
- Common coupling
- Control coupling
- Stamp coupling
- Data coupling
BEST
Content Coupling
Content coupling occurs when one class modifies the inner state of a class it depends on directly (as opposed to using the public interface). For example:
public class Student {
String name, email;
int id;
int notificationsReceived;
}
public class StudentNotifier() {
public notifyStudent(String message, Student s) {
Email notificationEmail = new Email(message, s.email);
s.notificationsReceived++;
}
}
Here, one class is directly responsible for reading and writing information to another class’s private data. This is bad for a number of reasons:
1) Any changes to the private implementation details of Student will cause changes to propagate to any classes that use its data. 2) Any other class could theoretically be reading and writing to the same data, making interactions with Student potentially complicated and difficult.
Instead, we may want to relocate the notifyStudent function:
public class Student {
private String name, email;
private int id;
private int notificationsReceived;
public notify(String message) {
Email notificationEmail = new Email(message, email);
notificationsReceived++;
}
}
public class StudentNotifier() {
public notifyStudent(String message, Student s) {
s.notify(message);
}
}
Common Coupling
Two items are “content coupled” if they have read and write access to the same global data. An easy illustration of this is showing the use of static global variables which is used as a communication source between modules. Note that for this to be common coupling, we specifically need both read and write access. For example, public constant values, which cannot be changed, do not violate Common Coupling.
public class Main {
public static String filename;
public static void main(String[] args) {
filename = args[0];
MyFileReader mfr = new MyFileReader();
mfr.run();
}
}
public class MyFileReader {
public void run() {
FileReader fileReader = new FileReader(Main.filename);
BufferedReader br = new BufferedReader(fileReader);
...
}
}
The above is bad because, by giving public access to the static field filename, any class in our entire project could read or write to this field. As a general rule, static values should generally be limited to constants (which cannot be changed, therefore have no risk). Instead, we can replace global variables with passed arguments (such as to a constructor or method argument):
public class Main {
public static void main(String[] args) {
filename = args[0];
MyFileReader mfr = new MyFileReader(filename);
mfr.run();
}
}
public class MyFileReader {
private String filename;
public MyFileReader(String filename) {
this.filename = filename;
}
public void run() {
FileReader fileReader = new FileReader(Main.filename);
BufferedReader br = new BufferedReader(fileReader);
...
}
}
Note that “global data” doesn’t inherently mean global variables, however. For example, if two different classes are both directly interacting with a shared database, and both classes can add, remove, and alter records in the same table, this is common coupling (note that some will call this external coupling and distinguish it from common coupling, but the core problem is the same). This is because if there is a data error, it is not clear which module created the corruption. However, this can be resolved by creating one module that handles database interactions with other modules that need to interact with. We will discuss this idea further when discussing the Singleton Design Pattern.
Control Coupling
Control coupling is when one module passes some kind of flag (typically a boolean) to another module which is used in control flow. This can be boolean variables or enum (enumerated types). However, it can also be any other value sent to a function strictly and transparently for the purposes of control flow navigation.
Here is an example of control coupling making two modules more tightly coupled.
public class Employee {
private String name, jobTitle, email, homeAddress;
public String getInfo(String infoType) {
infoType = infoType.toLowerCase();
switch(infoType) {
case "name":
return name;
case "email":
return email;
case "title":
return jobTitle;
case "address":
return homeAddress;
default:
throw new IllegalArgumentException();
}
}
}
This is very tightly coupled, because in order to use the function getInfo correctly, you have to understand it’s internal structure and options. By contrast, simply having getName(), getJobTitle(), etc. as getting functions would be significantly better and simpler to understand. Thus, in this case, even though the input is a String, it still effectively a “flag” value that is only used by control flow.
Now, in some cases, it is not possible to completely avoid this type of coupling. However, we can isolate that control coupling to only a single method using a Factory Method Pattern, and use polymorphism to keep the interactions with the product class abstract and not reliant on the underlying class type.
public enum FileType { CSV, XML, JSON, TXT };
public class FileWriterFactory {
public FileWriter getFileWriter(FileType fileType) {
return switch(fileType) {
case CSV -> new CSVFileWriter();
case XML -> new XMLFileWriter();
case JSON -> new JSONFileWriter();
case TXT -> new TXTFileWriter();
default -> throw new IllegalArgumentException();
};
}
}
In the above example, assume that all of the file writers specified are concrete implementations of some abstract FileWriter class.
Why Boolean arguments are bad
Another reason boolean arguments are bad is that usage of functions with boolean arguments often lacks understandability.
public void makeBurger(boolean hasCheese) {
if (hasCheese) {
cookBurger();
addCheese();
assembleSandwich();
} else {
cookBurger();
assembleSandwich();
}
}
A reason that a bad function is that any function using it must know the intent of the boolean variable used. In a vacuum, a call to this function may look like makeBurger(true). It’s incredibly unclear what the purpose of true is, here. Instead, we can break this up into two separate functions:
public void makeCheeseBurger() {
cookBurger();
addCheese();
assembleSandwich();
}
public void makeHamBurger() {
cookBurger();
assembleSandwich();
}
Stamp Coupling
Stamp Coupling exists when a module passes a data structure to another module, when the entire data structure is not needed.
public class Student {
private String name, email;
private StudentRecord record;
public StudentRecord getRecord() { return record; }
}
public class StudentRecord {
private int credits;
private List<Grade> gradeList;
public List<Grade> getGradeList() { return gradeList; }
}
public class GPACalculator() {
public double calculateGPA(Student s) {
StudentRecord record = s.getRecord();
List<Grade> gradeList = record.getGradeList();
...
return gpa;
}
}
In the above case, any Client class that calls calculateGPA is passing unnecessary information, like a students name, email, and credits. This is problematic because this means that the GPACalculator class is now coupled to and dependent on the interfaces of both Student and StudentRecord, in addition to its necessary Dependency on the class Grade. This means now if any of the three classes change, this change will propagate to GPACalculator. On the other hand, if instead, calculateGPA only accepted a List<Grade>, now it is a much more stable interface, as only changes to the interface of Grade and List could affect it.
Data Coupling
The gold standard: all communication between modules is done via passing the minimum amount of data as arguments and returning exactly the data needed. A good example of this is Math.sqrt(double number), which takes in a number, and returns its square root. The modules otherwise do not share any data. Additionally, data passed is not mutated by the call.
This insures that any action taken by the “called” method, with the exception the data it returns, will not affect the execution of the calling method. Additionally, the calling method only needs to understand the intent of the parameters at a functional interface level.
This allows us to develop both modules independently, without worrying about behavior of one module complicating the behavior of another.
Mutability and Coupling
One issue of coupling relates to mutability, that is objects where the State can change. For example:
List<Integer> myList = new ArrayList<>(List.of(8, 6, 7, 5, 3, 0, 9));
Collections.sort(myList);
System.out.println(myList); // prints 0, 3, 5, 6, 7, 8, 9
Here, we are sorting the variable myList. The module Collections has a sorting method. However, this sorting is done in-place. That means that we are actually modifying the value of myList in another module.
This is worse than data coupling, because the relationship is more complicated. Rather than handling side effects locally, we are relying on another module to handle our side effects. While this is a built-in Java function, it would be easier to understand and use this method correctly if this method returned a new List, rather than modifying our existing one. Of course, this creates a trade-off: if we make the usage of sort create a new list, it now uses twice as much memory for our list.
Temporal Coupling
Here is one that some code I have written for class is particularly bad about (intentionally so, as I planned to address it in class). This is based on code I have encountered in the wild:
public class GuessResult {
private String guess;
private String answer;
public String getGuess() {
return guess;
}
public void setGuess(String guess) {
this.guess = guess.toUpperCase();
}
public String getAnswer() {
return answer;
}
public void setAnswer(String answer) {
this.answer = answer.toUpperCase();
}
public LetterResult[] getGuessResult() { ... }
}
In order to use the above code, you would have to do something like:
GuessResult gr = new GuessResult();
gr.setGuess("BOXER");
gr.setAnswer("MATCH");
LetterResult[] result = gr.getGuessResult();
That is, you specifically have to call setAnswer and setGuess before you can call getGuessResult, otherwise you get an exception. This means that the interface of this module is more complicated than it needs to be. Consider the following change:
public class GuessResult {
private String guess;
private String answer;
public GuessResult(String guess, String answer) {
this.guess = guess.toUpperCase();
this.answer = answer.toUpperCase();
}
public LetterResult[] getGuessResult() { ... }
}
Now what does the usage look like?
GuessResult gr = new GuessResult("BOXER", "MATCH");
LetterResult[] result = gr.getGuessResult();
In this case, we have turned temporal coupling into data coupling, as it is no longer possible to get the function calls out of order. You have to call the constructor first anyways to instantiate the object. But after that, the object cannot be in an incorrect state. If you want to call this function again, simply create a new GuessResult object. A note that there is a trade-off here, as instantiating a new object, as opposed to reusing an older one, comes with a memory and time cost. However, from a maintainability perspective, the second approach is more maintainable.
How does code like the first example happen? It happens due to an over-adherence to simple-sounding principles. This particular example emerged because of trying to follow principles in Clean Code. Specifically, from Chapter 3 where Bob Martin argues that Monadic functions (functions with one argument) are generally better than Dyadic functions (functions with two arguments). If you take that idea out of context and try to force one-argument functions, that’s how you end up with setups like:
GuessResult gr = new GuessResult();
gr.setGuess("BOXER");
gr.setAnswer("MATCH");
LetterResult[] result = gr.getGuessResult();
Conclusion
In the last two units, we talked about cohesion and coupling. We want our classes to be highly cohesive (that is, parts of the modules highly intradependent to describe one behavior) and loosely coupled (that is, relationships to other modules are as simple as possible, ideally just simple functional calls).